Evaluating and improving LLM confidence calibration in educational dialogue coding.
Hongming (Chip) Li1Dr. Huan Kuang2Dr. Anthony F. Botelho1
1 University of Florida · VIABLE Lab
2 Florida State University
When a model says “confidence: 0.9,” can we believe it?
Who we are
A quick hello from our team.
Hongming (Chip) LiPhD CandidateUniversity of FloridaDr. Huan KuangAssistant ProfessorFlorida State UniversityDr. Anthony F. BotelhoAssistant ProfessorUniversity of Florida
A University of Florida (VIABLE Lab) and Florida State University collaboration, spanning AI in education, learning analytics, and educational data mining.
First, what we are actually doing
We ask the model to label a message, and to say how sure it is.
A student message
“Can you give me a Java example of a for-loop?”
→
Humans coded it
example
one of nine categories, by expert coders
→
The model answers
example confidence 0.9
its label, plus how sure it says it is
That last number is the whole talk. The model grades its own answer, and we ask a simple question. When it says 0.9, is it really right about 90% of the time?
So why does that one number matter so much?
If we could trust it, a human would only need to check the doubtful cases.
That is the prize. Accept what the model is sure about, and send a human only what it is unsure about. At the scale of real datasets, that saves enormous effort. But it all rests on one thing: the confidence has to actually track correctness.
Traditional MLA trained probability
An old-style classifier learns its confidence from data, so we have decades of tools to check it and fix it.
but
An LLMA number written as text
The model just writes “0.9,” the same way it writes any word, with no real look inside itself. So we cannot assume it means anything. We have to check.
And one more reason to care. In education we often cannot send student data to a commercial API, so we are pushed onto local, open models, and those turn out to be exactly where this number is shakiest.
So how do you even check a confidence number?
We ask two things, and the second one is the surprise.
Question 1 · honestyIs 0.9 really 90%?
Line up everything it called “0.9” and check how often it was actually right. If it is right far less than 90% of the time, it is overconfident.
+
Question 2 · orderingAre higher scores at least more often right?
Even if every number is inflated, the ranking can still be useful. If its 0.9s beat its 0.7s, we can still send the lowest scores to a human. This is what triage needs, and it is what AUC measures.
Keep this distinction in your pocket. A model can be badly overconfident and still rank usefully. So when results come up, watch the ranking (AUC), not just the size of the gap.
That gives us three questions, in order
Diagnose it, explain it, then try to fix it.
RQ1Diagnose
Can we trust the confidence these models report when they code?
RQ2Explain
If not, why, and can we fix it just by changing the prompt?
RQ3Intervene
If the prompt is not enough, can we reach inside the model and help?
RQ1 · first, what are we grading against?
633 student–AI dialogues, expert-coded into nine categories.
633
Real student prompts
Messages students sent to ChatGPT for help in a graduate intro computer science course. Authentic, messy, in-the-wild data.
9
Mutually exclusive codes
collaboration, exploration, investigation, resource, framing, value judgment, default, example, and NA. A scheme refined over a prior study.
2
Expert human coders
Independent coding by trained qualitative researchers. Inter-rater reliability ran from Cohen’s κ of 0.65 to 0.94, substantial to strong.
One prompt, three models, the way practitioners do it.
Every model gets the same prompt. It predicts a category, reports a confidence from 0 to 1, and gives a brief rationale. We use greedy decoding (temperature 0) so runs are reproducible.
gpt-5-minigemini-3-flashllama-3.1-8b
We study verbalized confidence, the number the model writes, rather than token logits. It is the common paradigm in applied workflows, and it is the one signal we can compare fairly across closed APIs and open weights.
Study 1 · question 1 · is 0.9 really 90%?
No. All three models were consistently overconfident.
0.89–0.92
Mean stated confidence, nearly identical across all three models.
0.34–0.52
Actual accuracy on a hard nine-way task (chance is about 0.11).
The gap
A confidence–accuracy gap of 0.40 to 0.55, and ECE points the same way across every model we tested.
In our data, overconfidence showed up across all three models rather than in just one. A practical reading is that the raw number is best not taken as a probability.
Study 1 · question 2 · but can it still rank?
Sometimes, and accuracy did not predict it.
On AUC, the ability to rank correct above incorrect, the two closed models land in a range that is usable for triage. The open-weight model sits much closer to chance.
One twist gemini was the most accurate model (0.52) yet ranked its own correctness a little worse (AUC 0.67) than gpt-5-mini (0.44 accuracy, 0.69 AUC).
gpt-5-mini · AUC 0.69Moderate, enough to help prioritize review.gemini-3-flash · AUC 0.67Moderate, despite the highest accuracy.llama-3.1-8b · AUC 0.57Close to chance, so triage offers limited value.
Knowing the answer and knowing when you know it look like different abilities here, so it helps to evaluate calibration on its own rather than infer it from accuracy.
Study 1 · and where do the mistakes happen?
It confuses the subtle codes, and stays just as confident.
example and collaboration recognized well; finer codes confused.most accurate, but still leans on a few categories.sparsest diagonal, the weakest agreement with experts.
Don’t read the cells; just the pattern. Bright diagonal means correct. Concrete codes like example get a bright box; subtle intent codes like investigation smear sideways. The catch: the model was just as confident on the codes it got wrong, so the confidence is not warning us. So can we just ask it to be less sure?
Study 2 · RQ2 · can we just tell it to calm down?
The obvious fix: show the model an example of being less confident.
People are swayed by a number they have just seen. Ask someone “is this worth more or less than $100?” and their guess lands near $100. That pull is called an anchor.
Our prompt already shows the model an example of the answer format. So we simply changed the confidence in that example, and watched whether the model drifted toward it.
Baselineconfidence: [0–1]no number shownHigh anchorconfidence: 0.95a high exampleLow anchorconfidence: 0.05a low example
If the model is just being swayed like a person, a low example should pull it down. Does it?
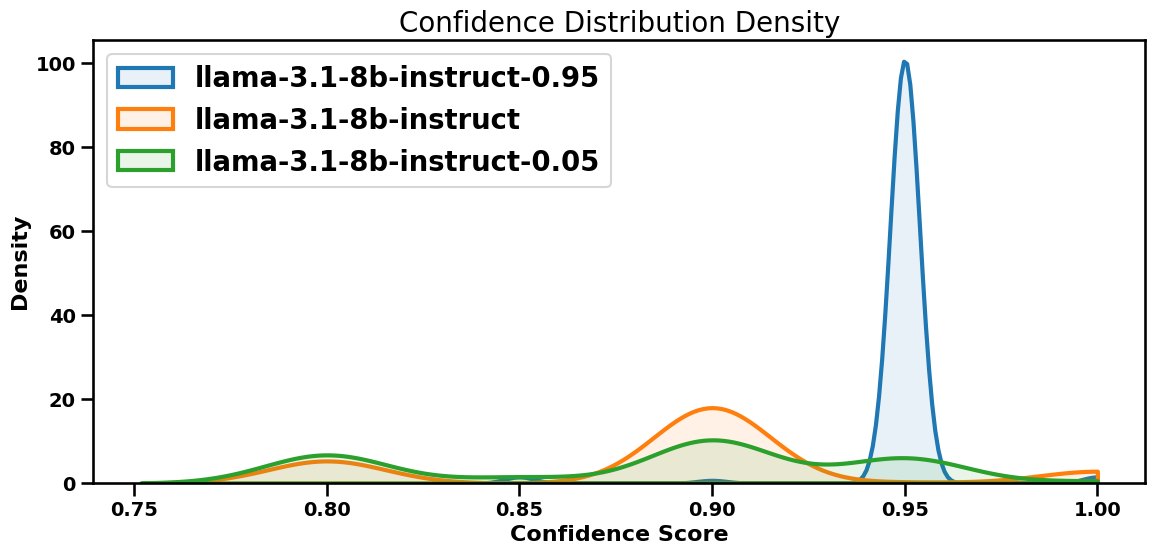
Study 2 · the result
It follows high anchors and ignores low ones.
The asymmetry is striking in our data.
High anchor (0.95)96.5% of outputs land at exactly 0.95, a near mode collapse.
Low anchor (0.05)0% adoption. Outputs return to the default 0.80 to 0.95 range.
Blue: 0.95 anchor, a single sharp spike. Green: 0.05 anchor, no peak there at all. Orange: baseline.
Study 2 · so what does that tell us?
The confidence is a habit, not a sense of doubt.
The model copies a high example because high confidence is what it always says here. It ignores the low one because low confidence just is not part of its habit. In fact, at baseline 99% of its answers are only three numbers (0.80, 0.90, 1.00). It is repeating what confident text looks like, not measuring how sure it is. That is why a prompt cannot talk it out of being overconfident.
Words can’t fix it the habit is too strongso where does that leave us?Maybe go deeper past the words, into the model
Study 3 · words did not work, so we open the model up
Can we nudge the model toward its more honest self?
With an open model we can watch its internal “thinking layers” as it answers, not just read the text. The bet: when it is being honest, those middle layers look one way; when it is overconfident, they look another. If so, we can find that difference and gently push every answer toward the honest side. No retraining.
01Watch a middle layer
As the model answers all 633 items, record one middle “thinking” layer (we used layer 16 of 32).
02Compare
Group its honest moments versus its overconfident ones.
03Get a “be honest” direction
The difference between those two groups is a single direction we can dial.
04Nudge
Turn that dial a little on every answer, as it runs. No retraining, no new data.
Think of it as a faint “be more honest” dial we found inside the model. We build it on half the data and test on the other half. It needs to see inside the model, so it works only on open weights, the very setting our field is often limited to anyway.
Study 3 · the honest result
It moved the needle, but only a little.
The direction was real: it pushed ranking the right way on held-out data, in both settings we tried. But the gain is small, and the model stays badly overconfident. In our setting, this is not a fix.
So we say it plainly a genuine signal is in there, the nudge just does not move it far. We would rather show you that than oversell it.
AUC 0.565 → ~0.585A real but small step, about +0.02.Spearman ρ 0.13 → ~0.16Nudged the right way on held-out data.Gap unchangedStill very overconfident. Not a fix on its own.
A cautious read. Some calibration-relevant signal seems to live in the representations, and a light-touch nudge can surface a little of it without retraining. We see it as a complement to prompting, not a fix.
Synthesis · one coherent story
Verbalized confidence looks more like a learned prior than an uncertainty estimate.
Study 1 found overconfidence across all three models, with ranking ability that varies. Study 2 offered a reason, confidence concentrates on a few high values the model treats as plausible. Study 3 suggested some of that signal can be surfaced from inside the model. Three studies, one through-line.
Overconfident across modelsShaped by a priorPartly recoverable from within
Being upfront about scope
Where this holds, and where it might not.
One datasetIntro CS prompts, nine categories. Other domains may differ.Single-turn, one modelOne open model, zero-shot. We did not test multi-turn, or an LLM judging another LLM.Steering was modestA real but small effect, shown within one dataset.
Why we chose this lens
The simplest setting, on purpose.
Richer setups, an LLM as judge, multiple agents, multi-turn checks, may well calibrate better. We deliberately studied the plainest case practitioners actually use, because that is where the surprising habit shows up most clearly.
And honestly we would love to see these ideas tried in those richer setups, and on other coding tasks. Our code is open for exactly that.
If you remember one slide, this one
Four things to take back to your own coding.
Use it to rank, not to trust
A “0.9” is not a 90% chance. Don’t auto-accept on it. Do use it to sort cases and send the least-sure ones to a human.
from Study 1 · the honesty question
Check the ordering on your own data
That sorting only helps if higher confidence really is more often right (what AUC measures). It worked for the closed models, barely for the open one. So measure it before you rely on it.
from Study 1 · the ranking question
Don’t hand-write a confidence example
A fixed number in your prompt just feeds the habit; the model copies it or ignores it. Leave it an open range, and the same caution likely applies to other self-rated scores.
from Study 2 · the prompt cannot fix it
Going inside the model may help
Editing internal states nudged it the right way, but only a little here. Promising, not a fix. The code is open, so please try it on your model and task.
from Study 3 · past the prompt
Thank you
Questions?
The one line: an LLM’s confidence reads more like a learned habit than real doubt, so use it to rank what a human checks, not as a probability. Happy to dig into the metrics, the anchoring, or the steering code.
Hongming (Chip) Li · hli3@ufl.eduHuan Kuang · hkuang2@fsu.eduAnthony F. Botelho · abotelho@coe.ufl.edu
Scan to explore
Paper, PDF, figures, and the open-source steering code
 Hongming (Chip) LiPhD CandidateUniversity of Florida
Hongming (Chip) LiPhD CandidateUniversity of Florida Dr. Huan KuangAssistant ProfessorFlorida State University
Dr. Huan KuangAssistant ProfessorFlorida State University Dr. Anthony F. BotelhoAssistant ProfessorUniversity of Florida
Dr. Anthony F. BotelhoAssistant ProfessorUniversity of Florida



 Paper, PDF, figures, and the open-source steering code
Paper, PDF, figures, and the open-source steering code